OSCAR-Net: Object-centric Scene Graph Attention for Image Attribution

Figure 1. Seeing is not always believing. We propose OSCAR-Net: an image hashing network for matching images circulating online to a trusted database, in order to fight visual misinformation. OSCAR-Net hashes are invariant to benign ‘non-editorial’ transformations (e.g. warping, flipping, padding left column) but sensitive to subtle manipulation of objects (middle column) in images. OSCAR-Net learns to ignore the former but pays attention (right column) to the latter.
TLDR;
We present highlights from our ICCV 2021 paper on fighting visual misinformation using a novel tamper-sensitive hashing algorithm. Our object-centric model decomposes an image into a scene graph of objects and relationships, and uses attention to explicitly capture subtle manipulations meant to mislead users in a compact hash.
See links for our paper, code, and dataset IDs (50mb).
Abstract
Images tell powerful stories but cannot always be trusted. Matching images back to trusted sources (attribution) enables users to make a more informed judgment of the images they encounter online. We propose a robust image hashing algorithm to perform such matching. Our hash is sensitive to manipulation of subtle, salient visual details that can substantially change the story told by an image. Yet the hash is invariant to benign transformations (changes in quality, codecs, sizes, shapes, etc.) experienced by images during online redistribution. Our key contribution is OSCAR-Net (Object-centric SCene graph Attention for image attRibution); a robust image hashing model inspired by recent successes of Transformers in the visual domain. OSCAR-Net constructs a scene graph representation that attends to fine-grained change of every object’s visual appearance and their spatial relationships. The network is trained via contrastive learning on a dataset of original and manipulated images yielding a state of the art image hash for content fingerprinting that scales to millions of images.
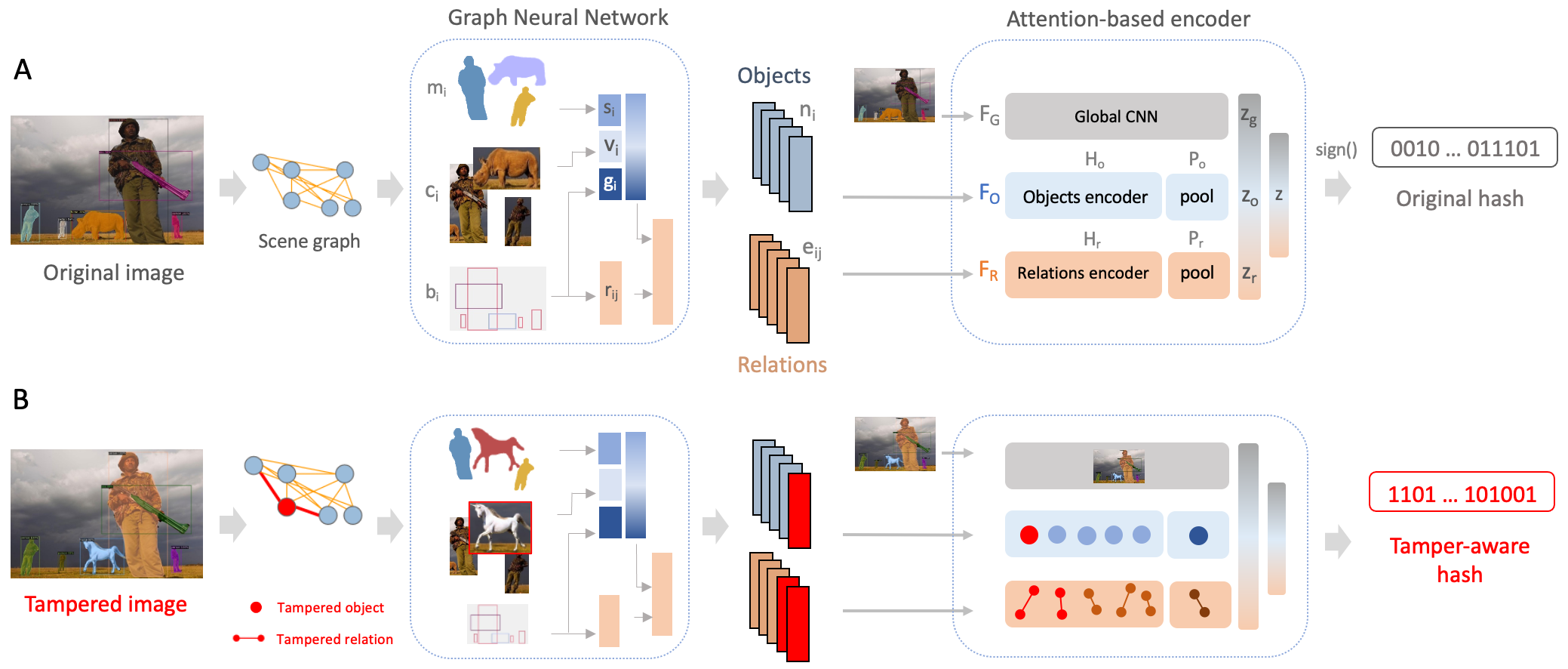
Figure 2. Object-centric Scene Graph Attention Network (OSCAR-Net). In A, our object-centric hashing method first decomposes animage into a fully connected scene graph of N detected objects using their appearance (ci), masks (mi) and bounding box geometry (bi).The whole image, N object and N2 relation embeddings are fed into the 3-stream attention-based encoder, comprised of a global CNNbranch FG, an object encoder FO and a relation encoder FR to encode each stream to zg, zo, zr, respectively. A single 64-D embeddingzis created, and passed through asignfunction to create a 64 bit image hash. In B, we indicate how tampered objects and relations areexplicitly captured in the scene graph and allow for fine-grained manipulations to produce substantially different hash compared to theoriginal hash.

Figure 3. Examples of original (left) and manipulated (right, high-lighted) images in PSBattles24K. From the top-down: change ingaze, geometry and pose (see coloured box)
Dataset
Link to image IDs (4.7M = ~50mb) from Adobe Stock images. See Adobe APIs on how to retrieve the images.Additional examples
(left) grad cam visualizations of manipulated images, (middle) benign transforms of original, (right) manipulated images






